Why Servers Are Consuming More Power? | Analyzing TDP Growth Over Time
Why Servers Are Consuming More Power, depending on where you are in a server refresh cycle or building out AI clusters, one thing is clear. Liquid cooling may get much attention, but power is often the long pole and biggest challenge in build-outs. While many factors drive this, one big one is that servers use more power with increased performance and capacity. In this article, we will look at dual socket server CPUs and NVIDIA SXM GPUs and how their TDPs have increased over time.
Server CPU TDPs are Rapidly Increasing
I have tried to make this chart a few times but have been paralyzed by indecision. Trying to nail a population to chart when it comes to charting TDP over time. Is an 8-socket Xeon EX low-volume high-end part going to make the cut? What about a workstation-focused part? At the end of the day, I went back through STH, looked at the types of chips we were deploying in dual-socket servers, and decided to use those. Are these charts perfect? Absolutely not. There are judgment calls being made to try mapping a progression of server CPUs over time.
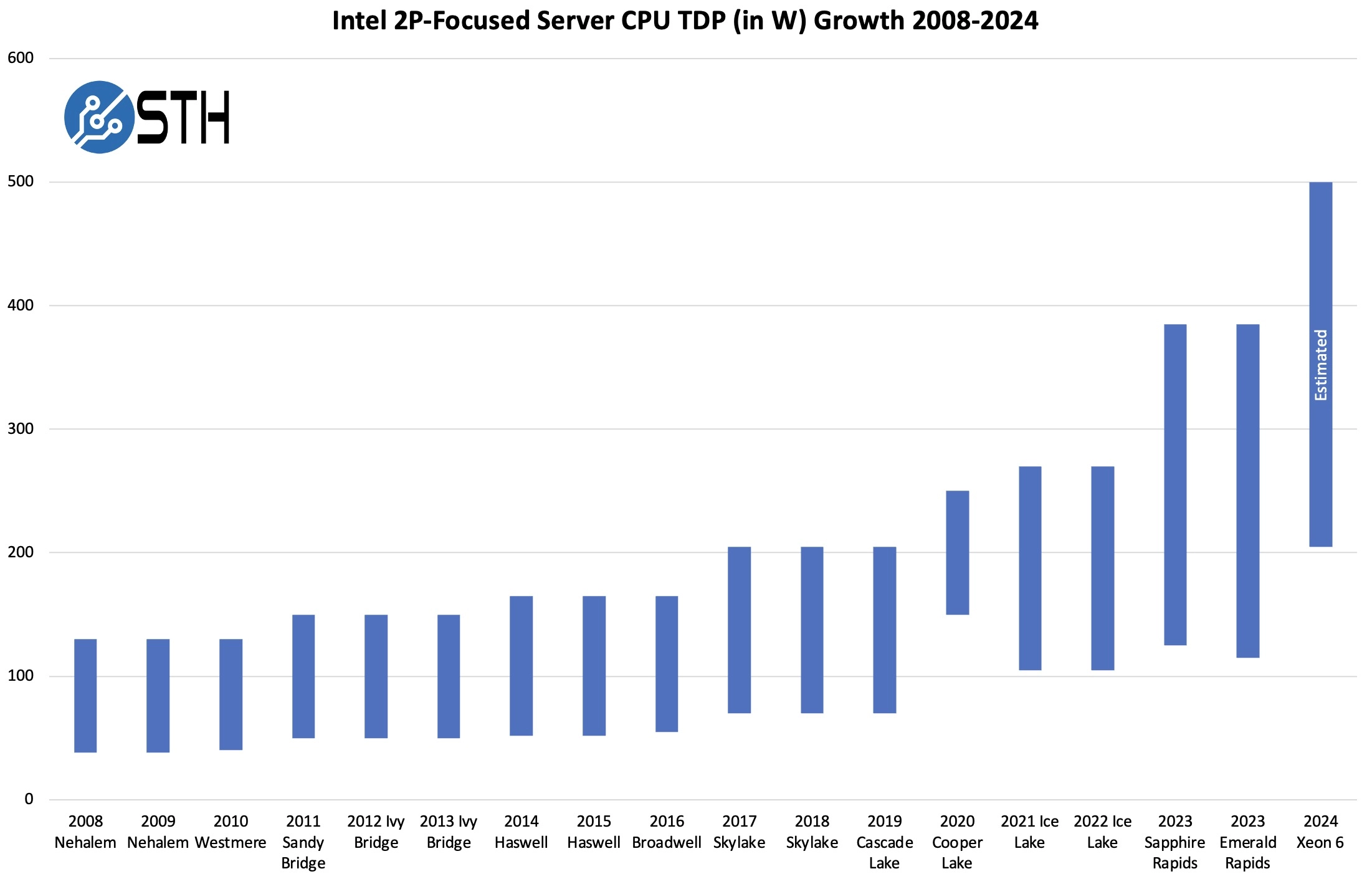
Why Servers Are Consuming More Power, taking a look at the dual-socket Intel Xeon TDPs over time, it should be clear that the trendline is accelerating to a degree that we simply did not see for over a decade.
Why Servers Are Consuming More Power, between 2008-2016, power consumption remained relatively stable. Skylake (1st Gen Intel Xeon Scalable) in 2017 was the first generation where we saw a notable increase in TDP. After Cascade Lake in 2019, TDPs have been racing upward, both at the higher and lower ends. Cooper Lake was largely based on Cascade Lake, but had a few enhancements and was deployed at Facebook for example. One could rightly argue that this was primarily a public launch for 4-socket servers (4P), but we added it in. If you want to imagine the chart without Cooper Lake, then replace the 2020 bar with Cascade Lake, and you would have four years of TDP stagnation. Why Servers Are Consuming More Power, starting with Ice Lake in 2021, both the top and bottom end SKUs saw their TDPs increase.
A quick note here is that while we have previously talked about this quarter’s Granite Rapids-AP hitting 500W max TDP, and Q4’s AMD EPYC-Next (Turin) at 500W, these are still unreleased products, and we do not have the full stacks. We just put a plug for the low TDP range and used both companies talking about 500W as the high-end. That may change.
Taking a look at the AMD side, here is what we would see charting these parts out. Given that the Operton 6000 series was popular at the time, and we did many G34 reviews back in the day, we are using those for older parts. Why Servers Are Consuming More Power, when the Intel Xeon E5-2600 came out in 2011, we heard server vendors say that the Xeon E5 was displacing the Opteron 6000 series.
The Turin low-end TDP might be a bit low, but what is clear is that the TDP is going up. If you look at this in comparison to the Intel chart above, it is easy to see that AMD was ratcheting up TDP faster than Intel. In the industry, you may have heard that before the latest Xeon 6E launch, AMD is more efficient. Why Servers Are Consuming More Power, that is because AMD EPYC Rome to Genoa/ Genoa-X/ Bergamo had a significant process lead and was able to pack many more cores in a slightly higher TDP. As an example, the top-end 2019 Cascade Lake Xeon 8280 was a 205W part with 28 cores, or about 7.3W/ core. AMD EPYC 7H12 was a HPC focused 64-core part at 280W, or about 4.4W/ core. While it used more power, the power efficiency went up significantly.
GPUs are Following TDP
GPUs are another area where TDPs have been increasing significantly. Although we do not normally pre-share performance data, we wanted to validate that we are using the right SXM GPU power consumption and years with NVIDIA, so we sent this chart and got the OK. Why Servers Are Consuming More Power, GPUs are often announced and become widely available in different quarters, and NVIDIA GPUs frequently use configurable TDP, so making the chart we wanted to validate this was directionally correct.
Why Servers Are Consuming More Power, moving from 300W to 700W may seem in-line with the CPU TDP increases, another aspect is to remember that there are usually eight GPUs in a SXM system. In 2016, as NVIDIA was transitioning to SXM, the typical deep learning servers were 8-way or 10-way GeForce RTX 1080 Ti servers before NVIDIA’s EULA and hardware changes pushed the market to data center GPUs. These systems were often 2.4-3.1kW systems.
Why Servers Are Consuming More Power, we looked at the newer version of that design in our NVIDIA L40S review last year.
Why Servers Are Consuming More Power, a modern AI server is much faster, but it can use 8kW. That is pushing companies to upgrade to liquid cooling to lower power consumption and upgrade their rack power solutions.
In 2025, we fully expect these systems to use well over 10kW per rack as each of the eight accelerators start to tip the 1kW TDP mark. In North America, there are still a lot of 15A/20A 120V racks that cannot even power a single power supply of these large AI servers.
While we often discuss CPU and GPU TDPs, there is much more happening behind the scenes.
ColoCrossing excels in providing enterprise Colocation Services, Dedicated Servers, VPS, and a variety of Managed Solutions, operating from 8 data center locations nationwide. We cater to the diverse needs of businesses of any size, offering tailored solutions for your unique requirements. With our unwavering commitment to reliability, security, and performance, we ensure a seamless hosting experience.
For Inquiries or to receive a personalized quote, please reach out to us through our contact form here or email us at sales@colocrossing.com.

